各位都應該有看過網路新聞的留言板吧?底下除了針對新聞的實質留言以外,還充斥著各種針對執政者、意見相左的人、甚至不認識的路人的謾罵批評等等,與新聞內容並無太大關聯的意見。
如果我們今天想要從留言觀察群眾對於該則新聞的看法,例如「因為這幾天地震有感,政府是否要加強預防的政策力道」議題,我們是不是應該要把前述這種無關聯的資料過濾掉呢?
同樣的道理適用在大多數的分析情境,即使我們已經有記錄、即便記錄很大量,仍然要進行資料清洗的環節。理由在於,不論我們選擇哪一種分析方法,都要避免這些資料污染我們的結果。
除了工程師的經歷外,筆者過往亦曾處理為時不短的資料標記,大致總結出會得出最好的訓練結果的資料,必須至少符合以下兩點之一:
量多:多到標記錯誤或是不乾淨的資料造成的負面影響,可以被忽略不計。精確:如果量沒辦法提高,就勢必得注意資料的品質,避免雜訊或是標記錯誤對分析結果造成影響。回到筆者先前的記錄,我們可以設想以下的資料,不應該做為分析素材:
另外資料清洗也包去除每筆資料資料本身的雜質。以下圖為例:

我們可以看到,短短五行內,就有許多英文的句號「.」。原來是手機的輸入法在連續輸入空格的時候,會自動在已輸入過的句子後面加上一個英文句號。雖然一般情形來說確實很貼心,但多餘的句號都會影響我們人類判讀了,更何況是機器!所以必須過濾掉。
為此同時,還要保留第一個英文句號,作為小時分鐘的區隔。
再一次以上圖為例,我們可以看到,每一行就是獨立的一串文字。要不是有筆者在前幾篇向各位介紹我們目前資料形態,不然任誰來看大概只能看出這是一串時間,但也僅止於是一串時間,並沒有意義。
如果我們將資料添加上欄位資訊,變成像下圖這樣:
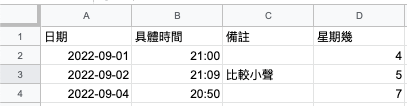
是不是這些資料就有了生命!
我們結構化的目的,在於賦予這些資料被利用的可能,也就是他們意義。

